GPT-2 Sometimes Fails at IOI
tl;dr: For Lisa, GPT-2 does not do IOI. GPT-2 fails to perform the IOI task on a significantly nonzero fraction of names used in the original IOI paper.
Code for this post can be found at https://github.com/ronakrm/ioi-enumerate.
Unintentionally continuing the trend of “following up” on the IOI paper, I ran GPT-2 Small on all possible inputs that fit the original BABA templates, PLACE/OBJECT tokens, and set of names for Subjects and Indirect Objects. This results in 9 million strings, and instead of just looking at the mean logit diff between the subject and indirect object tokens, let’s look at the distribution.
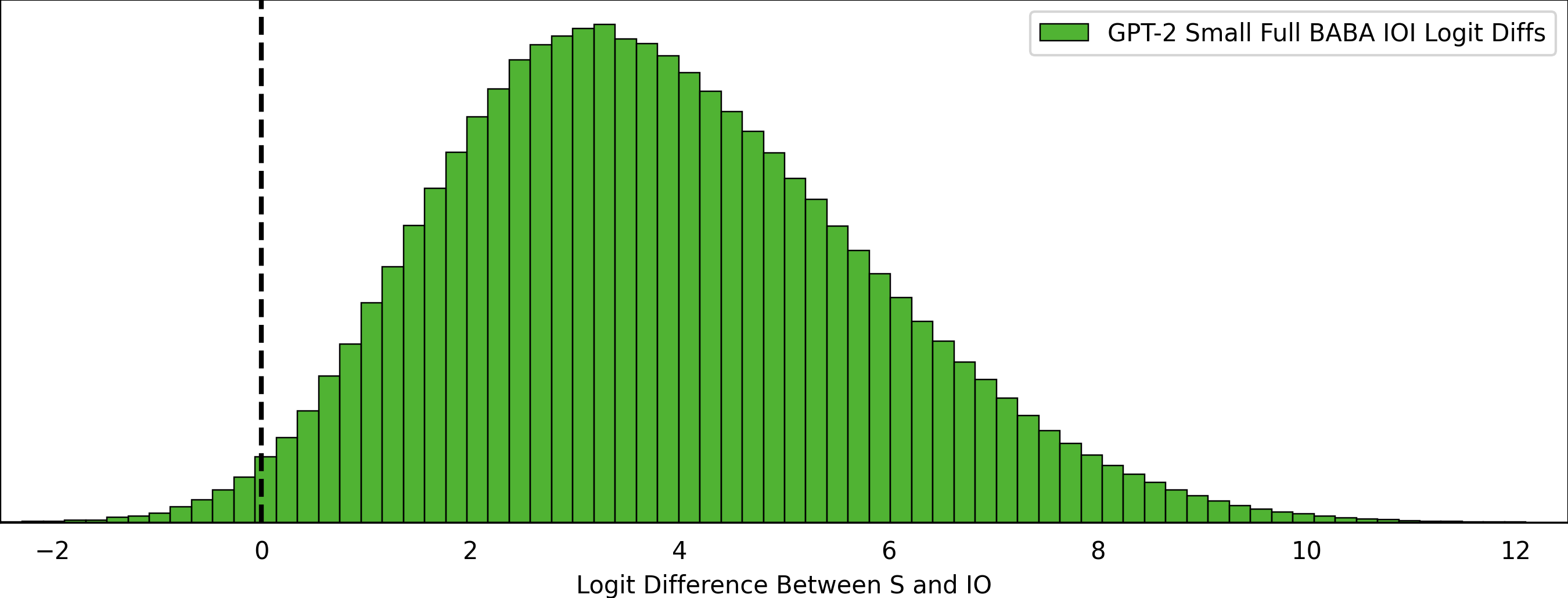
These look pretty decent, but there’s obviously some mass below zero! For what percent of the 9 million inputs does GPT-2 incorrectly predict the Subject instead of the Indirect Object as the higher logit? 1.348%, or about 125,000 out of the ~9 million sentences!
We can dig in a bit deeper and try to identify if a structured subset of the data is where the model consistently fails. We can identify these subsets by looking at the conditional means and finding the ones that are furthest from either the global mean or the when that condition is inverted. In other words, we can split our data into groups which have the subject as X and not X, the IO as X and not X, etc., and then sort by the mean difference between these groups to get an idea. (check out the notebook in the repo)
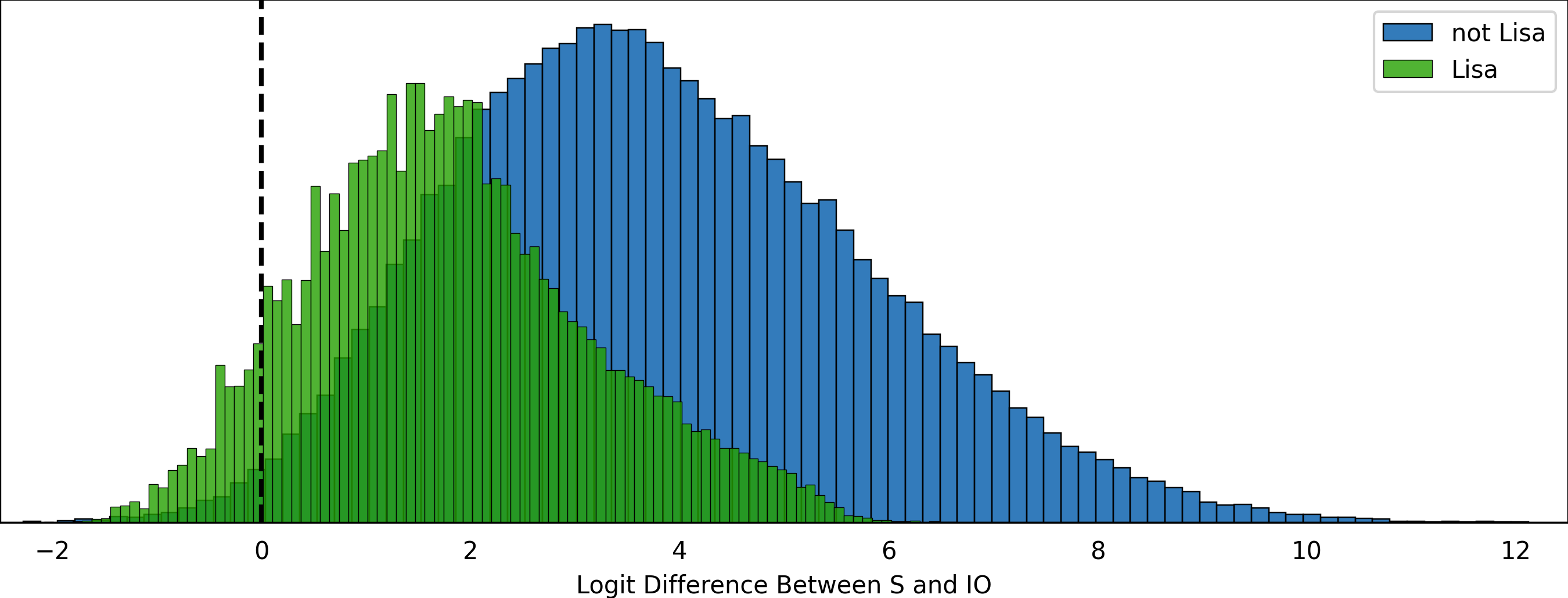
If we restrict our data to this subset and do this procedure again,
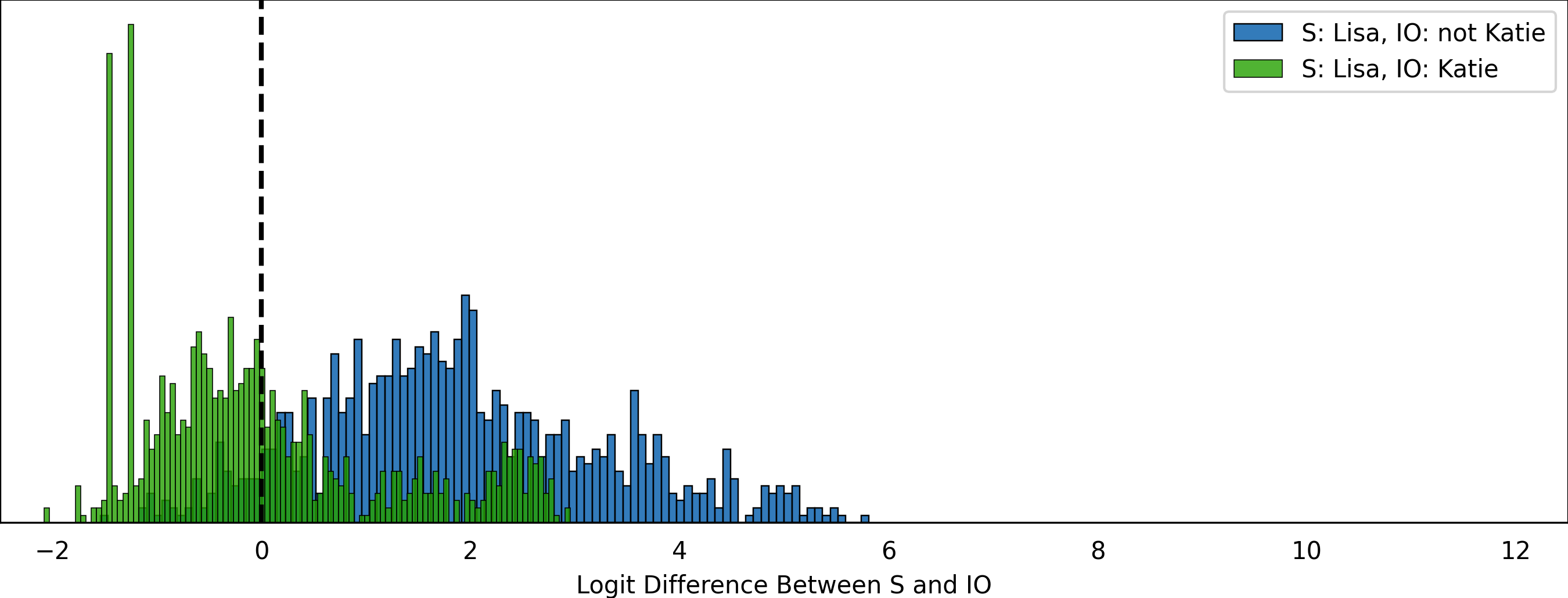
we can find out that in a large portion of cases where the subject is Lisa and the indirect object is Katie, GPT-2 Small fails to perform the IOI task correctly. In fact there appear to be a number of other Indirect Object names that consistently perform poorly when the Subject is Lisa:
| IO | mean | std | alt_mean | alt_std |
|---|---|---|---|---|
| Katie | 0.017770 | 1.187264 | 1.817443 | 1.349228 |
| Alicia | 0.196236 | 1.065318 | 1.815603 | 1.352604 |
| Michelle | 0.206026 | 0.938098 | 1.815502 | 1.353694 |
| Samantha | 0.232368 | 1.106246 | 1.815231 | 1.352706 |
| Lindsay | 0.275709 | 0.938980 | 1.814784 | 1.354523 |
The notebook and other code in the repository have slightly more exploration, and is reasonably easy to run and extend so feel free to poke!
A Quick Check on Larger Models
For GPT-2 Medium, the number of examples with a negative logit difference is 4143, or 0.044% of all ~9M samples.
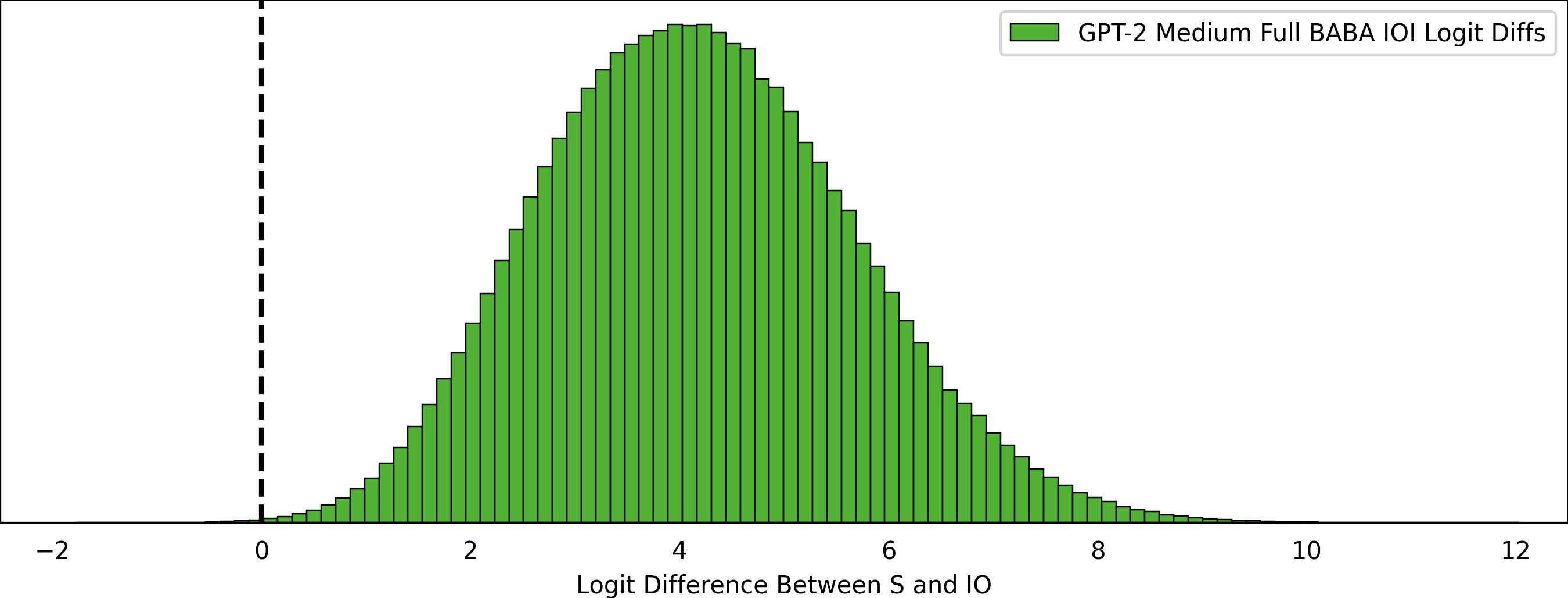
And for GPT-2 Large, 5986, or 0.064% of all ~9M samples.
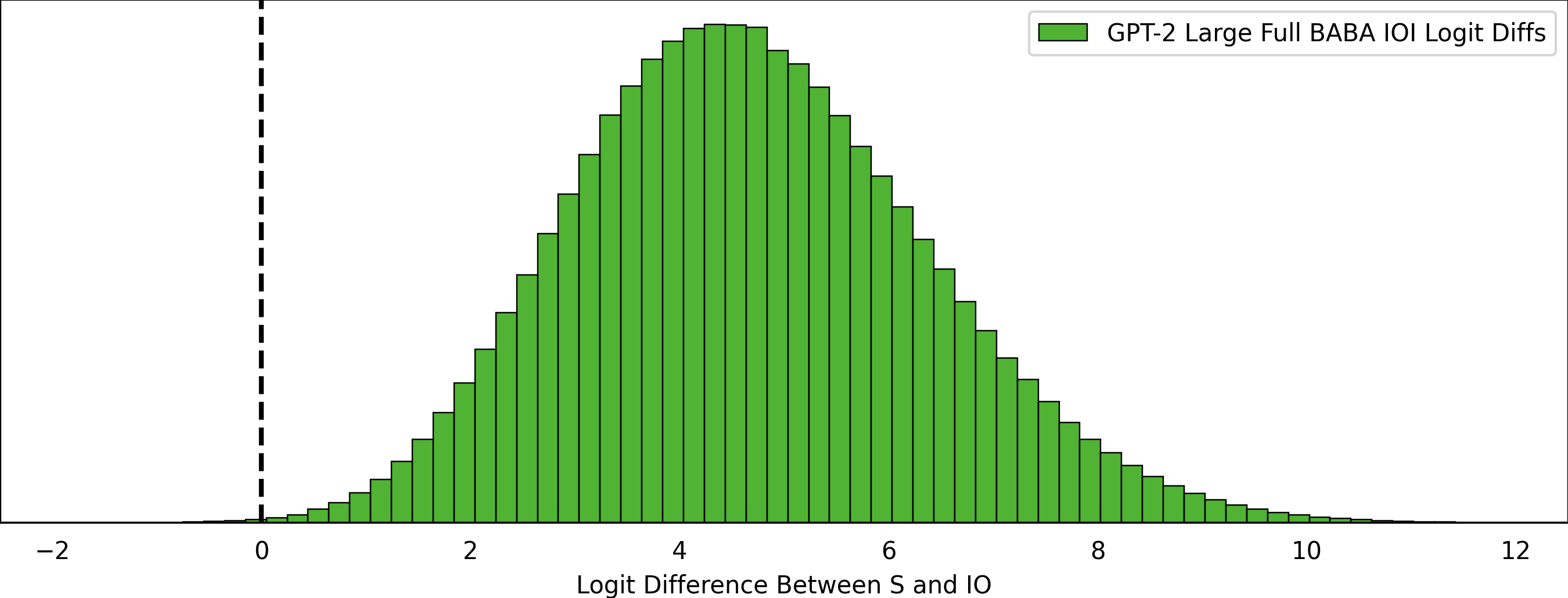
For both of these slicing by first-order obvious dataset groups did not show anything interesting (check the notebook in the repo).
Final Thoughts
When we can, we should brute force all inputs that make reasonable sense and look at the full distribution. I’m becoming more interested generally in bounding worst-case behaviors as a safety angle: this is one toy setup where the worst-case is not being handled correctly. If your name is Lisa or Katie you may feel this more concretely, let alone if your name is uncommon, non-Western, or multi-token. As we worry more and more about extreme tail-risk failure modes, it’s a good idea to keep things like this in mind, and perhaps ideas in fairness and more mainstream machine learning may be good “model organisms” for demonstrating and studying these failure modes.
I think it’s good to worry about these kinds of issues as we attempt to scale interpretability approaches to large models, and I’m glad that new approaches for ensuring the robustness and faithfulness of interpretability results are becoming more popular.
Specifically I’m excited that work like Hypothesis Testing the Circuit Hypothesis in LLMs and Transformer Circuit Faithfulness Metrics are not Robust are becoming a bit more mainstream; I share a lot of their thoughts and am excited and optimistic to see this grow!